Animal detection model with YOLOv7
The idea of this interactive tool has been to learn how to build a simple first application of the state-of-the-art Object detection framework YOLOv7, using the pre-trained model they provided and the public dataset “Monkey, Cat and Dog Detection” from Kaggle to retrain the model so that it now allows for detect and classify monkeys, since COCO dataset, what is the one to train YOLOv7 does not include these animals. In addition, it was also necessary to carry out a learning process on how to deploy and make inference on that model through a web service.
The next tool is intended for real-time video application, since the model used offers several advantages and improvements over previous versions of this framework.
Sample examples





Model prediction
What is YOLO?
You Only Look Once (YOLO) is a state-of-the-art, real-time object detection algorithm introduced in 2015 by Joseph Redmon, Santosh Divvala, Ross Girshick, and All Farhadl in their famous research paper “You Only Look Once: Unified, Real-Time Object Detection” . YOLO is not a single architecture but a flexible research framework written in low-level languages. The framework has three main components: the head, neck, and backbone.
In 2020, AlexeyAB took up the YOLO torch from the original authors maintaining his fork of YOLOv3 for a while before releasing YOLOv4, an upgrade on the previous model. WongKinYiu entered the CV research stage with a Cross Stage Partial networks, which allowed YOLOv4 and YOLOv5 to build more efficient backbones. From there, WongKinYiu steamrolled ahead making a large contribution to the YOLO family of research with Scaled-YOLOv4, that was the first paper on which they both collaborated, followed by some other notables and important improvements until YOLOv7.
The following is a brief description of the most significant contributions that were made in the YOLOv7 paper:
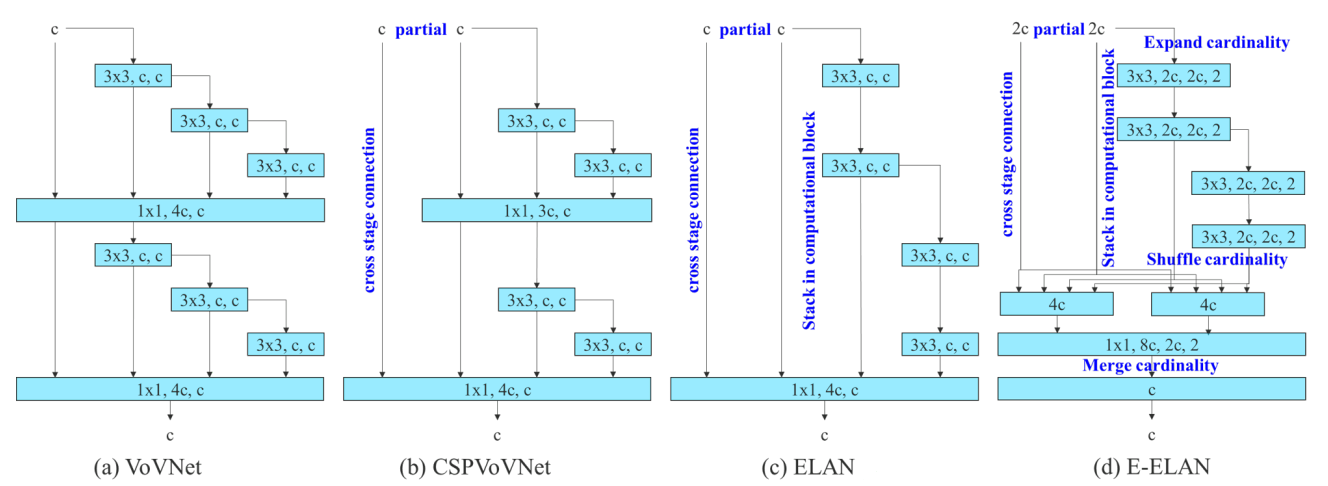
Extended Efficient Layer Aggregation
In YOLOv7, the authors build on research that has happened on this topic, keeping in mind the amount of memory it takes to keep layers in memory along with the distance that it takes a gradient to back-propagate through the layers. The subsequent prominent development in architecture search, from VovNet model, is called ELAN and YOLOv7 extends that and calls it E-ELAN. The conclusions drawn from the ELAN paper were that by controlling the gradient path, a deeper network can learn and converge effectively. E-ELAN uses expand, shuffle, and merge cardinality to achieve the ability to continuously enhance the learning ability of the network without destroying the original gradient path.
Model Scaling Techniques
The primary purpose of model scaling is to adjust some attributes of the model and generate models of different scales, scaling up and down in size, to meet the needs of different levels of accuracy and inference speeds. Typically, object detection models, like Google’s famous architecture called EficientNet, considers the depth, the width and the resolution that the network is trained on.
The strategy used by EfficientNet is not suitable for concatenation-based architecture, when depth scaling is performed the output width of computational block also increase, what will cause the input width of the subsequent transmission layer to increase. In YOLOv7, the authors propose a technique that is, when performing model scaling on concatenation-based models, only the depth in a computational block needs to be scaled, and the remaining of the transmission layers is performed with the corresponding width scaling. The evolution of Model scaling for concatenation-based models is shown in the following image.

Re-parametrization planning
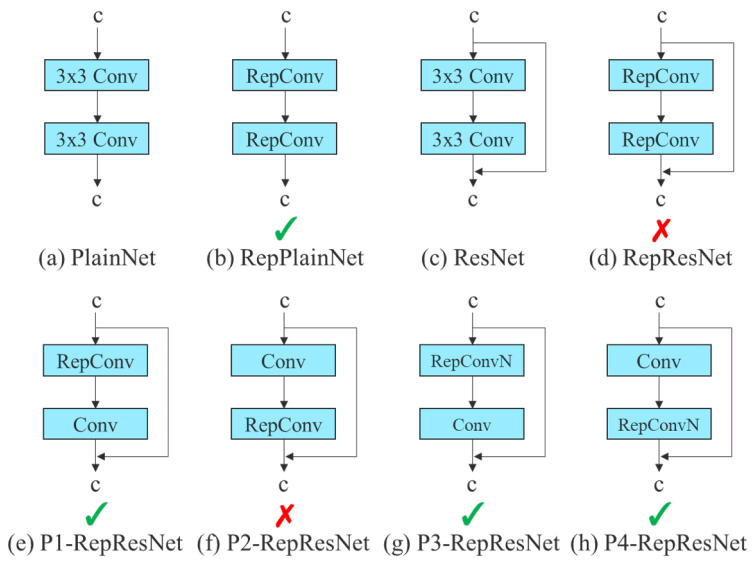
Re-parameterization techniques involve averaging a set of model weights to create a model that is more robust to general patterns that it is trying to model. In research, there has been a recent focus on module level re-parameterization where piece of the network have their own re-parameterization strategies.
The YOLOv7 authors used gradient flow propagation paths to analyze how re-parameterized convolution should be combined with different networks, leading to see which modules in the network should use re-parameterization strategies and which should not.
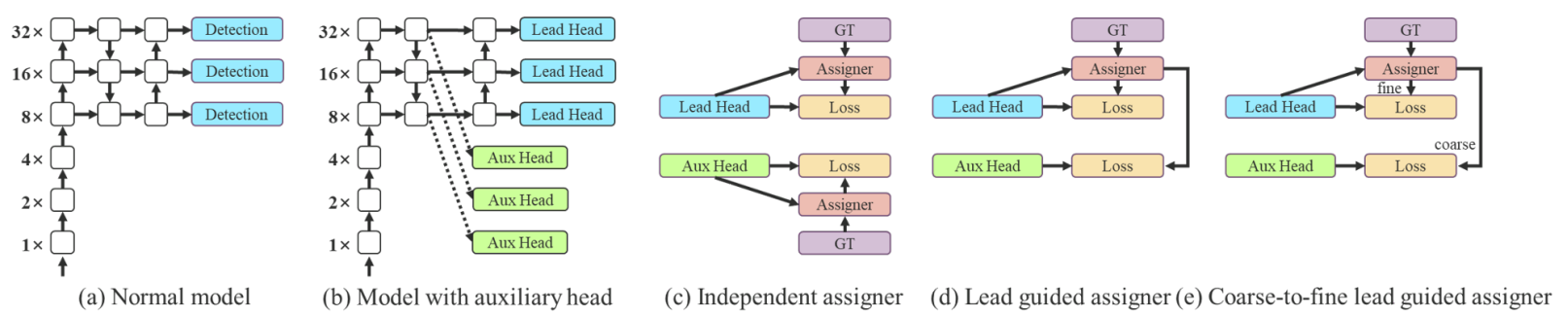
Coarse of auxiliary and fine for lead loss
Deep supervision is a technique that is often used in training deep networks. Its central concept is to add an extra auxiliary head in the middle layers of the network, and the shallow network weights with assistant loss as the guide.
YOLOv7 use lead head prediction as guidance to generate coarse-to-fine hierarchical labels, which are used for auxiliary head and lead head learning, respectively. By letting the shallower auxiliary head directly learn the information that the lead head has learned, the lead head will be more able to focus on learning residual information that has not yet been learned. In addition, the coarse-to-fine lead guided mechanism allows the importance of fine label and coarse label to be dynamically adjusted during the learning process and makes the optimizable upper bound of the fine label consistently higher than the coarse label.